
191: Mechanize
(view original Railscast)
Other translations:



In last week’s episode we used Nokogiri to extract content from a single HTML page. If you have more complex screen-scraping needs, for example retrieving data that requires you to log in to a site first, then this simple approach won’t work. This time we’ll use Mechanize to interact with a site so that we can extract the data from it.
The site we’ll use is Ta-da list. This is a simple to-do list application written by 37 Signals. We have already set up an account and created a list. If we want to view the list again we have to log in to the site and then click the name of the list on the home page.
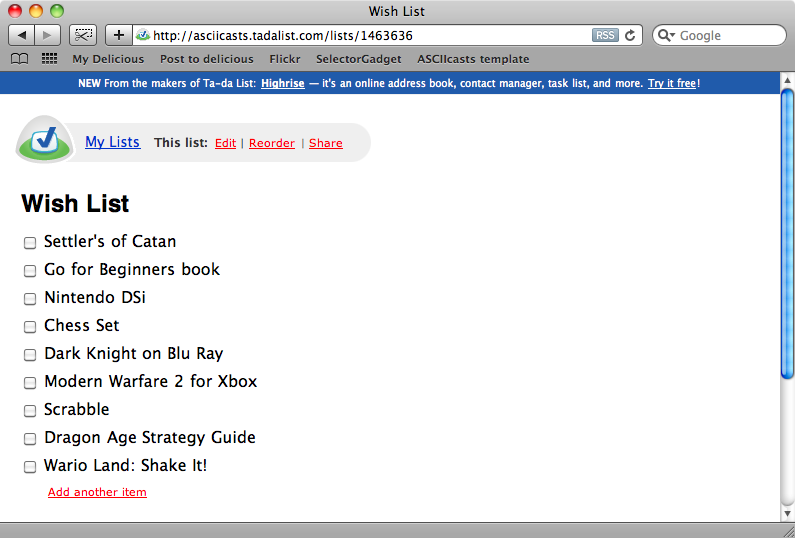
Our list contains a list of products that we want to automatically import into a Rails application. We’ll need to interact with Ta-da List to get the items then we can use the script we wrote in the previous episode to get a price for each product.
As the list is private we can’t just visit the list’s URL. We can see this if we use curl to try to retrieve the page.
$ curl http://asciicasts.tadalist.com/lists/1463636 <html><body>You are being <a href="http://asciicasts.tadalist.com/session/new">redirected</a>.</body></html>
So, as we can’t access the page directly we’ll need to log in to the application before we can access our list. This is where Mechanize comes in. Mechanize uses Nokogiri and adds some extra functionality for interacting with sites so that it can used to perform tasks like clicking links or submitting forms.
Mechanize is a gem and is installed in the usual way:
sudo gem install mechanize
Once it’s installed we can open up Rails’ console to see how it works. First we’ll require Mechanize.
>> require 'mechanize' => []
Next we’ll need to instantiate a Mechanize agent:
> agent = WWW::Mechanize.new
=> #<WWW::Mechanize:0x101c74780 @follow_meta_refresh=false, @proxy_addr=nil, @digest=nil, @watch_for_set=nil, @html_parser=Nokogiri::HTML, @pre_connect_hook=#<WWW::Mechanize::Chain::PreConnectHook:0x101c74190 @hooks=[]>, @open_timeout=nil, @log=nil, @keep_alive_time=300, @proxy_pass=nil, @redirect_ok=true, @post_connect_hook=#<WWW::Mechanize::Chain::PostConnectHook:0x101c74168 @hooks=[]>, @conditional_requests=true, @password=nil, @cert=nil, @user_agent="WWW-Mechanize/0.9.3 (http://rubyforge.org/projects/mechanize/)", @pluggable_parser=#<WWW::Mechanize::PluggableParser:0x101c74550 @default=WWW::Mechanize::File, @parsers={"application/xhtml+xml"=>WWW::Mechanize::Page, "text/html"=>WWW::Mechanize::Page, "application/vnd.wap.xhtml+xml"=>WWW::Mechanize::Page}>, @verify_callback=nil, @connection_cache={}, @proxy_user=nil, @pass=nil, @ca_file=nil, @request_headers={}, @user=nil, @cookie_jar=#<WWW::Mechanize::CookieJar:0x101c746b8 @jar={}>, @scheme_handlers={"https"=>#<Proc:0x00000001020c12c0@/Library/Ruby/Gems/1.8/gems/mechanize-0.9.3/lib/www/mechanize.rb:152>, "file"=>#<Proc:0x00000001020c12c0@/Library/Ruby/Gems/1.8/gems/mechanize-0.9.3/lib/www/mechanize.rb:152>, "http"=>#<Proc:0x00000001020c12c0@/Library/Ruby/Gems/1.8/gems/mechanize-0.9.3/lib/www/mechanize.rb:152>, "relative"=>#<Proc:0x00000001020c12c0@/Library/Ruby/Gems/1.8/gems/mechanize-0.9.3/lib/www/mechanize.rb:152>}, @redirection_limit=20, @proxy_port=nil, @history_added=nil, @auth_hash={}, @read_timeout=nil, @keep_alive=true, @history=[], @key=nil>
With our agent we can log in to our Ta-da list. To do this we’ll need to get the login page, enter a password and then submit the login form.
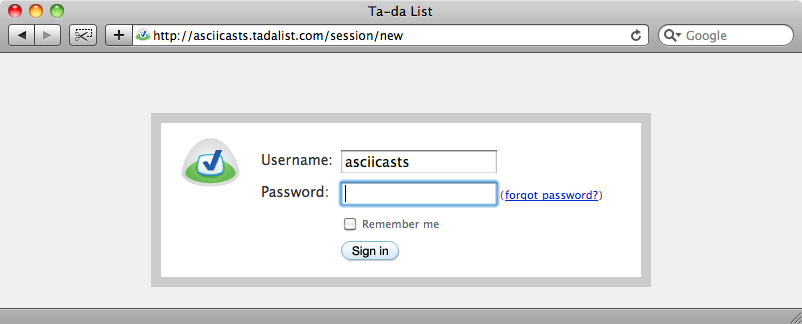
To get the contents of a page with a GET request we call agent.get, passing the page’s URL.
>> agent.get("http://asciicasts.tadalist.com/session/new")
=> #<WWW::Mechanize::Page
{url #<URI::HTTP:0x101c5c180 URL:http://asciicasts.tadalist.com/session/new>}
{meta}
{title "Ta-da List"}
{iframes}
{frames}
{links
#<WWW::Mechanize::Page::Link
"forgot password?"
"/account/send_forgotten_password">}
{forms
#<WWW::Mechanize::Form
{name nil}
{method "POST"}
{action "/session"}
{fields
#<WWW::Mechanize::Form::Field:0x1035f1708
@name="username",
@value="asciicasts">
#<WWW::Mechanize::Form::Field:0x1035ef4a8 @name="password", @value="">}
{radiobuttons}
{checkboxes
#<WWW::Mechanize::Form::CheckBox:0x1035eeb48
@checked=false,
@name="save_login",
@value="1">}
{file_uploads}
{buttons}>}>
This returns a Mechanize::Page object which includes all of the attributes for that page including, for our page, the login form.
Calling agent.page at any time will return the current page and we can call properties on this to access the various elements on the page. For example, to get at the forms on the page we could call agent.page.forms which will return an array of Mechanize::Form objects. As there is only one form on our page we can call agent.page.forms.first to get a reference to it. We’ll be making use of this form so we’ll assign it to a variable.
>> form = agent.page.forms.first
=> #<WWW::Mechanize::Form
{name nil}
{method "POST"}
{action "/session"}
{fields
#<WWW::Mechanize::Form::Field:0x1035f1708
@name="username",
@value="asciicasts">
#<WWW::Mechanize::Form::Field:0x1035ef4a8 @name="password", @value="">}
{radiobuttons}
{checkboxes
#<WWW::Mechanize::Form::CheckBox:0x1035eeb48
@checked=false,
@name="save_login",
@value="1">}
{file_uploads}
{buttons}>
If we look at the form’s fields collection in the output above we’ll see that the username field is already filled in, but that the password field is empty. Filling in a form field is done in the same way we’d set an attribute on a Ruby object. We can set the password field with
form.password = "password"
Submitting the form is equally simple: all we need to do is call form.submit. This will return another Mechanize::Page object.
>> form.submit
=> #<WWW::Mechanize::Page
{url #<URI::HTTP:0x10336ad68 URL:http://asciicasts.tadalist.com/lists>}
{meta}
{title "My Ta-da Lists"}
{iframes}
{frames}
{links
#<WWW::Mechanize::Page::Link "Highrise" "http://www.highrisehq.com">
#<WWW::Mechanize::Page::Link "Try it free" "http://www.highrisehq.com">
#<WWW::Mechanize::Page::Link
"Tada-mark-bg"
"http://asciicasts.tadalist.com/lists">
#<WWW::Mechanize::Page::Link "Create a new list" "/lists/new">
#<WWW::Mechanize::Page::Link "Wish List" "/lists/1463636">
#<WWW::Mechanize::Page::Link
"Rss"
"http://asciicasts.tadalist.com/lists.rss?token=8ee4a563af677d3ebf3ceb618dac600a">
#<WWW::Mechanize::Page::Link "Log out" "/session">
#<WWW::Mechanize::Page::Link "change password" "/account/change_password">
#<WWW::Mechanize::Page::Link "change email" "/account/change_email_address">
#<WWW::Mechanize::Page::Link "cancel account" "/account/destroy">
#<WWW::Mechanize::Page::Link "FAQs" "http://www.tadalist.com/help">
#<WWW::Mechanize::Page::Link
"Terms of Service"
"http://www.tadalist.com/terms">
#<WWW::Mechanize::Page::Link
"Privacy Policy"
"http://www.tadalist.com/privacy">
#<WWW::Mechanize::Page::Link
"other products from 37signals"
"http://www.37signals.com">}
{forms}>
This is the page that shows our lists so the next step is to click on the link for the list of products. The page as it appears in the browser is below. It can be helpful to follow along in the browser as you use Mechanize so that you can determine what to script next.
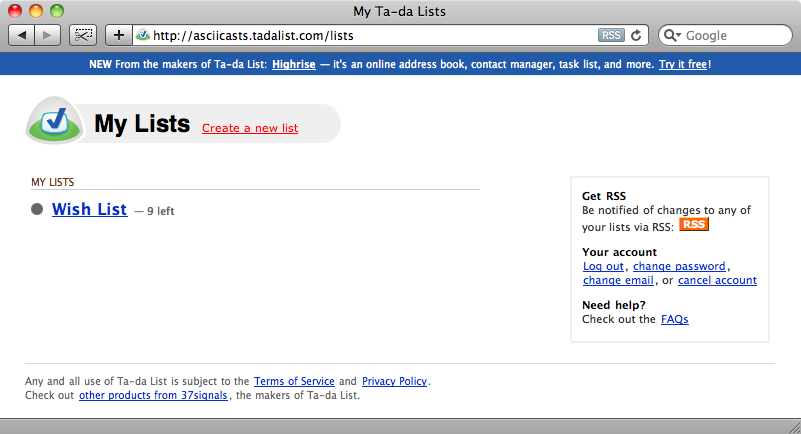
To get to the list we have to click on the “Wish List” link. There are several links on the page and we need to work out how to get the right link for Mechanize to click on. We could get all of the links with agent.page.links then iterate through them reading the text property of each until we find the one we want but there is an easier way to do this by using link_with:
>> agent.page.link_with(:text => "Wish List") => #<WWW::Mechanize::Page::Link "Wish List" "/lists/1463636">
The link_with method will return a link that matches a given condition, in this case a link with the text “Wish List”. A similar method exists for forms called, unsurprisingly, form_with and there are also the plural methods links_with and forms_with to find multiple links or forms that match a given condition.
Now that we’ve found our link we can call click on it to redirect to the list page. (Note that the long list of the page’s properties has been omitted below).
agent.page.link_with(:text => "Wish List").click
=> #<WWW::Mechanize::Page
{url
#<URI::HTTP:0x103261138 URL:http://asciicasts.tadalist.com/lists/1463636>}
We’ve finally reached our destination and have found the page we want to extract content from. We can use Nokogiri to do this but first we’ll need to find the CSS selector that matches the list items. As we did last time we can use SelectorGadget to determine the selector.
Clicking the first item in the list will select only that item but when we click the next one all the items are selected and we have the selector we need: .edit_item.
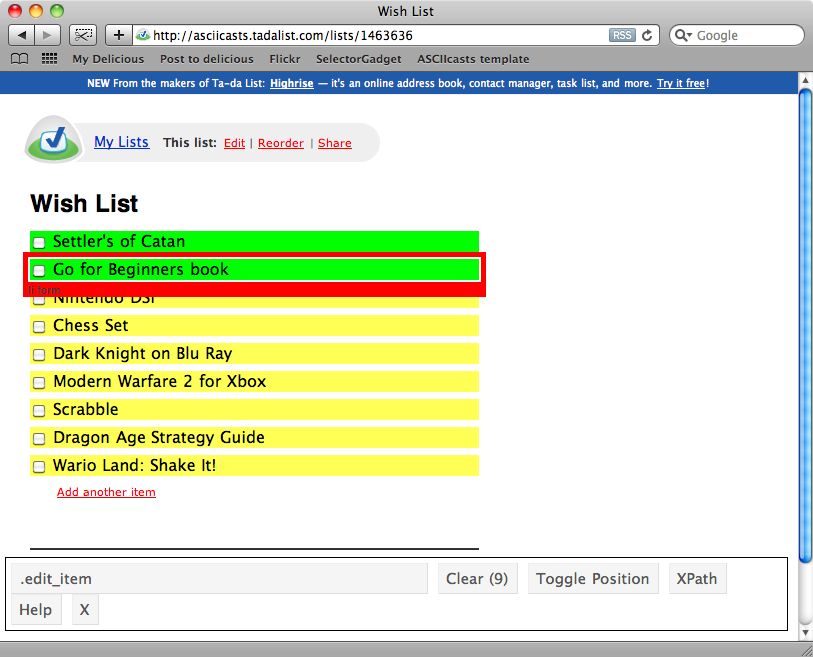
There are two methods on the page object that we can use to extract elements from a page using Nokogiri. The first of these is called at and will return a single element that matches a selector.
agent.page.at(".edit_item")
The second method is search. This is similar, but returns an array of all of the elements that match.
agent.page.search(".edit_item")
We have a number of items in our list so we’ll need to use the second of these. The command above will return a long array of Nokogiri::XML::Element objects, each one of which represents an item in the list. We can modify the output to produce something more readable.
>> agent.page.search(".edit_item").map(&:text).map(&:strip)
=> ["Settler's of Catan", "Go for Beginners book", "Nintendo DSi", "Chess Set", "Dark Knight on Blu Ray", "Modern Warfare 2 for Xbox", "Scrabble", "Dragon Age Strategy Guide", "Wario Land: Shake It!"]
By getting the text from each element and then calling strip on the text to remove whitespace we’re left with an array of the names of the items which is exactly what we want.
Integrating Mechanize Into our Rails Application
Now that we have an idea how to use Mechanize we can use what we’ve learned in a Rails application. We’ll use the same shop application we used in the last episode.
This time instead of scraping the prices for the items from another site we want to import new products from our Ta-da list. We’ll create a rake task to do this which we can put in the same /lib/tasks/product_prices.rake file as our other task, but what code should be in the task? Well, the code we’ve written in the console is a good place to start so we could start by copying the code from there.
The problem is that it’s difficult to extract the code we’ve written in the console as it’s mixed in with the output from each command. There is, however, a command we can enter that will return each command we’ve typed in.
>> puts Readline::HISTORY.entries.split("exit").last[0..-2].join("\n")
require 'mechanize'
agent = WWW::Mechanize.new
agent.get("http://asciicasts.tadalist.com/session/new")
form = agent.page.forms.first
form.password = "password"
form.submit
agent.page.link_with(:text => "Wish List").click
agent.page.search(".edit_item").map(&:text).map(&:strip)
=> nil
We now have a list of commands that we can copy into our rake task. We’ll then tidy up the script and loop through the items we retrieve from the list page, creating a new Product from each one.
desc "Import wish list"
task :import_list => :environment do
require 'mechanize'
agent = WWW::Mechanize.new
agent.get("http://asciicasts.tadalist.com/session/new")
form = agent.page.forms.first
form.password = "password"
form.submit
agent.page.link_with(:text => "Wish List").click
agent.page.search(".edit_item").each do |product|
Product.create!(:name => product.text.strip)
end
end
We could modify this script to remove the username and password and make them arguments that we pass, but we’ll leave that for now. Let’s see if our rake task works.
$ rake import_list (in /Users/eifion/rails/apps_for_asciicasts/ep191/shop)
There are no exceptions raised when we run the script so let’s reload the products page.
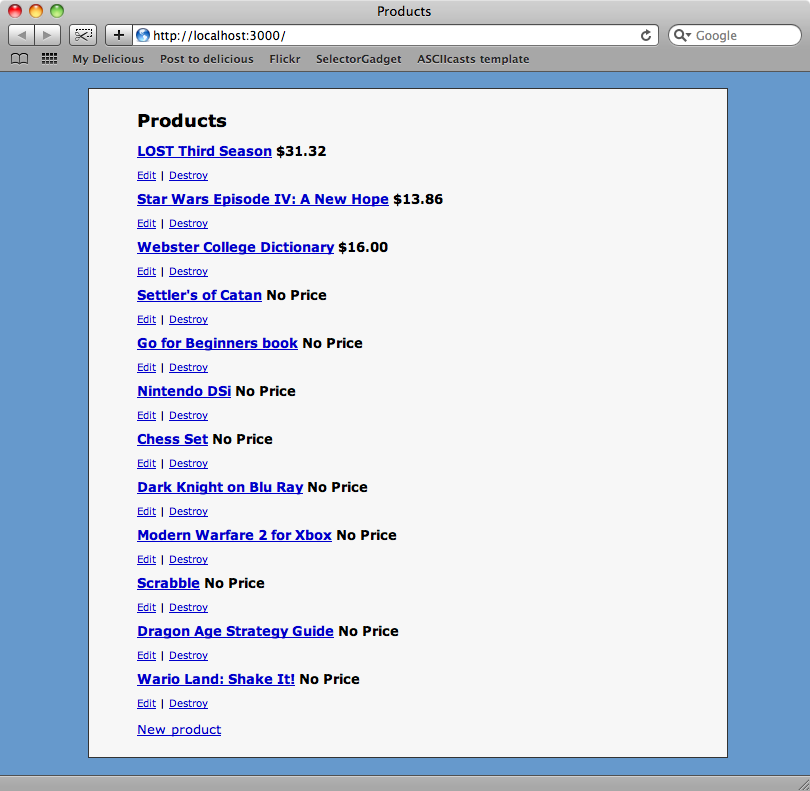
The script has worked: we now have a Product for each of the items in our list. If we run the rake task we wrote last week then we can get prices for all of our new items.
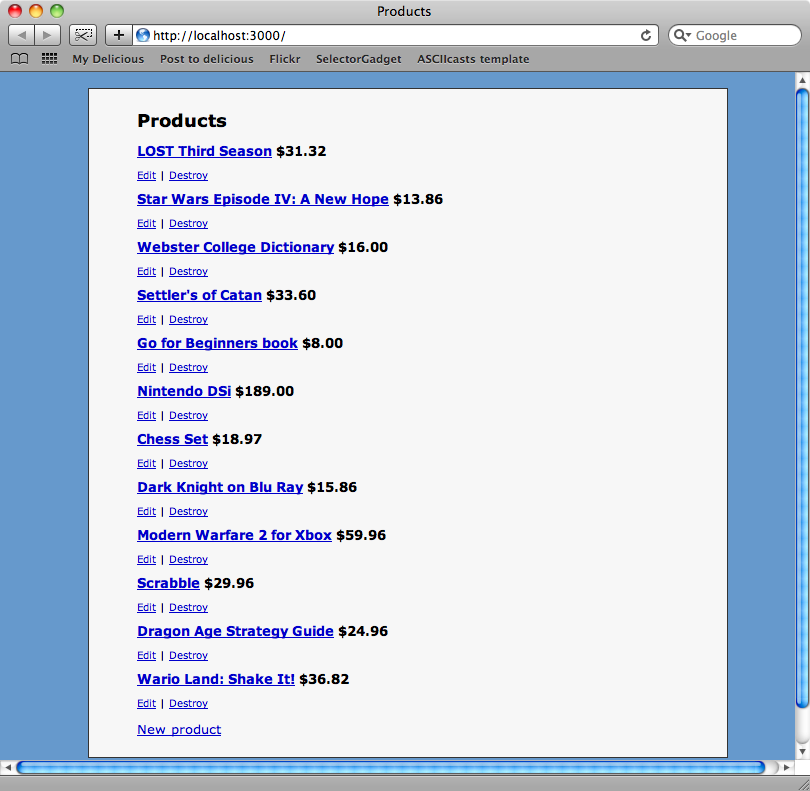
So we’ve reached our goal. We have used Mechanize and Nokogiri to navigate through several pages on a website, interacting with it to fill in forms and click hyperlinks and extracting the information we wanted. This is a great solution for scraping data from websites where no better alternative exists.