
190: Screen Scraping With Nokogiri
(view original Railscast)
Other translations:



In episode 173 [watch, read] we covered screen-scraping with the ScrAPI library. Screen-scraping is a popular subject and there are a number of gems and plugins to make it easier to do so this episode will cover the topic again but use different tools. After reading this episode you’re encouraged to go back and read the other one so that you can compare both approaches and see which one you prefer.
As we did last time we have an application that has a list of products without prices and we want to find prices for those products from another website, in this case walmart.com.
If we search for a product on Walmart’s home page we’re taken to a page that shows a list of matching products, along with their prices. We can use this page to retrieve those prices for our site.
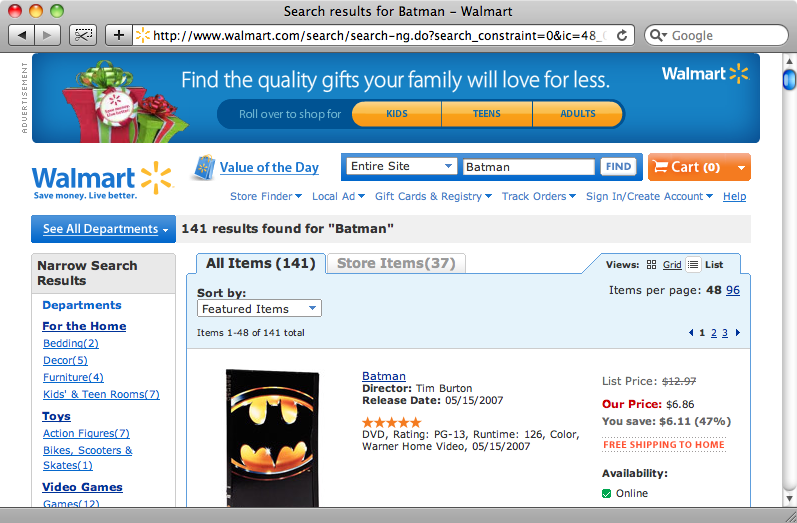
The results page for a search for “Batman”
As we mentioned back in the previous episode on screen-scraping it’s important to be sure that you have permission to scrape data from the site you’re planning to use. Some sites explicitly forbid retrieving data by screen-scraping so you should always check that you’re allowed to scrape data from the site before you start. If the site provides RSS feeds or an API that allows you to retrieve the data you’re after then this is always a better way to get that information. As neither of these options are available on Walmart’s site we’ll have to resort to screen-scraping.
Installing Nokogiri
Last time we used a library called ScrAPI to help us scrape data. This time we’re going to use Nokogiri, which can parse HTML and XML documents and extract content from them. Nokogiri is fast and the interface is different from ScrAPI’s in that it feels like we’re working more directly on the HTML document rather than doing everything through a DSL.
If you’re writing Rails applications on a Mac and running Snow Leopard then installing Nokogiri should be as straightforward as running
sudo gem install nokogiri
If you’re using an older version of OS X or a different operating system then you may have to manually install the libxml2 library beforehand and then specify its location when installing the Nokogiri gem. For example if you install libxml2 into /usr/local then the command may look like this:
sudo gem install nokogiri -- --with-xml2-include=/usr/local/include/libxml2 --with-xml2-lib=/usr/local/lib
If you need further help installing Nokogiri then take a look at installation tutorial where there are detailed instructions on installation for OS X, Linux and Windows.
Getting Started With Nokogiri
Once we have Nokogiri installed we can start to make use of it. Nokogiri can use either XPath or CSS3 selectors and the ability to use CSS selectors makes it a really good fit for extracting data from HTML documents.
We’ll start experimenting with Nokogiri in a plain Ruby script before bringing it in to our Rails application. Using the URL for the results for searching for “Batman” on Walmart’s site we’ll try to extract the page’s title.
require 'rubygems'
require 'nokogiri'
require 'open-uri'
url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=Batman&Find.x=0&Find.y=0&Find=Find"
doc = Nokogiri::HTML(open(url))
puts doc.at_css("title").text
As well as requiring the nokogiri gem we’ll require open-uri so that we can get the contents of a URL easily. We then create a new Nokogiri HTML document, passing it the contents of the search results page. With that Nokogiri document we can then use at_css, passing it the CSS selector "title" to retrieve the contents of the <title> element. The at_css method will return the first matching element and we can call .text on that element to get its text content. Finally we use puts to print out the text.
If we run our script we’ll see the contents of the page’s title.
Search results for Batman - Walmart
Let’s now try something a little more complex: retrieving the name and price of each product on the search results page. The first thing we’ll need to do is determine the CSS selectors that match the relevant parts of the page. In the previous episode on screen-scraping we used a Firefox plugin to do this, but this time we’ll make use of a bookmarklet called SelectorGadget. To use it we just drag the link from the site’s homepage into our browser’s bookmarks bar. As it’s a bookmarklet SelectorGadget will work with both Safari and Firefox.
So, back on the search results page we want to find the CSS selector that matches each item’s title. If we click on the first title on the page the selector that matches it will be shown. If we scroll down the page any other items that the selector matches will be shown. The selector we have, .prodLink, matches every title on the page which is exactly what we’re after so we’ve found the selector we want.
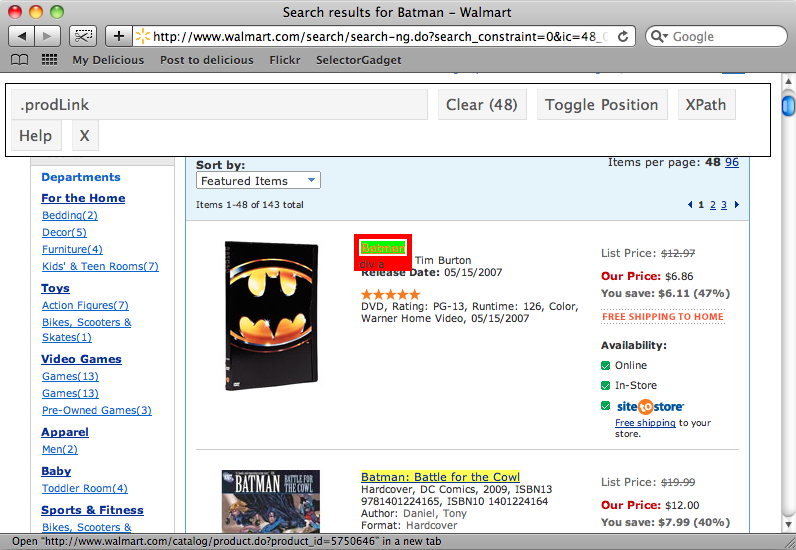
Now we’ll try to find a selector that matches the price of each item. This is a little more complicated. If we select one of the prices at the top of the page not all of the items’ prices are selected. When we select one of the unselected prices we’ll have all of the prices selected, but other elements on the page will be selected too. When we click on these to deselect them we’re finally left with just the prices selected and we can copy the selector that SelectorGadget has for us, which is .PriceXLBold, .PriceCompare .BodyS.
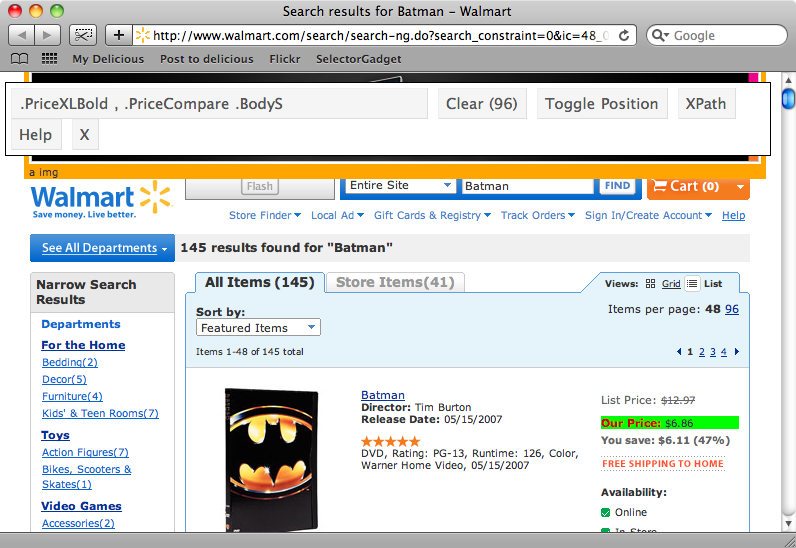
The final selector we need is one that matches each item in the list. If we click the first one then we’re given a selector that matches just the first item. Once we select the second item we’ll have a selector, .item, that matches all of the items on the page.
Now that we have the CSS selectors we need we can use them in our script to extract the information from the page. We’ll modify it to this:
require 'rubygems'
require 'nokogiri'
require 'open-uri'
url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=Batman&Find.x=0&Find.y=0&Find=Find"
doc = Nokogiri::HTML(open(url))
doc.css(".item").each do |item|
puts item.at_css(".prodLink").text
end
What we’re doing now is using the .item selector to loop through each item and then extracting the title from each with with the .prodLink selector. If we run our script again we’ll see the title of each item listed.
$ ruby test.rb Batman Batman: No Man's Land Batman: No Man's Land - Vol 03 Batman: No Man's Land - Vol 02 Fisher-Price Batman Lights and Sounds Trike Batman: Arkham Asylum (PS3) LEGO Batman (DS) LEGO Batman (Wii) DC Universe Batman / Superman / Catwoman / Lex Luthor / Two-Face Figures Batman Begins (Blu-ray) (Widescreen) LEGO Batman (Xbox 360)
Of course we also want the price for each item so we need to modify our script again:
require 'rubygems'
require 'nokogiri'
require 'open-uri'
url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=Batman&Find.x=0&Find.y=0&Find=Find"
doc = Nokogiri::HTML(open(url))
doc.css(".item").each do |item|
text = item.at_css(".prodLink").text
price = item.at_css(".PriceXLBold, .PriceCompare .BodyS").text[/\$[0-9\.]+/]
puts "#{text} - #{price}"
end
We get the title as before then use the CSS selector we have from SelectorGadget to get each item’s price. The element that contains the price also has some text in it, e.g. “Our price: $6.99” so we need to use a regular expression to match the dollar sign and any numbers or decimal points after it. When we run the script again we now have the title and price for each item on the page:
$ ruby test.rb Batman - $6.86 Batman: No Man's Land - $11.50 Batman: No Man's Land - Vol 03 - $11.50 Batman: No Man's Land - Vol 02 - $9.50 Fisher-Price Batman Lights and Sounds Trike - $43.21 Batman: Arkham Asylum (PS3) - $59.82 LEGO Batman (DS) - $19.82 LEGO Batman (Wii) - $19.82 DC Universe Batman / Superman / Catwoman / Lex Luthor / Two-Face Figures - $44.00 Batman Begins (Blu-ray) (Widescreen) - $11.32 LEGO Batman (Xbox 360) - $19.82
What if we want to extract the URL for each item too? Well, the element that holds the product’s title is an anchor element and it’s href attribute contains the URL for that item, so all we need to do is extract the value of that attribute. We can do this with the following line of code:
item.at_css(".prodLink")[:href]
Putting It All Together
Now that we’ve used Nokogiri to extract data from a web page we can use what we’ve written back in our Rails application to get the price for each product. We can do this through a Rake task, so in the app’s /lib/tasks directory we’ll create a new file called product_prices.rake to hold the task.
The code in the Rake task will be similar to the code in the Ruby script we wrote earlier. After giving our task a description we create the task itself. The task starts by running the :environment task to load the Rails environment. It then finds all of the products in the database that don’t have a price and loops though them.
For each product we want to get the appropriate search URL. To do this we’ll first need to escape the product’s name to make it safe to embed in a URL and we can use CGI::Escape to do this. Once we’ve put the URL together we can open it with Nokogiri and use the CSS selector from our Ruby script to extract the price. There’s a slight change to the regular expression so that we no longer include the currency symbol. Once we have the price we can update the product.
desc "Fetch product prices"
task :fetch_prices => :environment do
require 'nokogiri'
require 'open-uri'
Product.find_all_by_price(nil).each do |product|
escaped_product_name = CGI.escape(product.name)
url = "http://www.walmart.com/search/search-ng.do?search_constraint=0&ic=48_0&search_query=#{escaped_product_name}&Find.x=0&Find.y=0&Find=Find"
doc = Nokogiri::HTML(open(url))
price = doc.at_css(".PriceXLBold, .PriceCompare .BodyS").text[/[0-9\.]+/]
product.update_attribute(:price, price)
end
end
If we run the rake task now
rake fetch_prices
it runs without errors so let’s go back to our products page and see what’s happened.
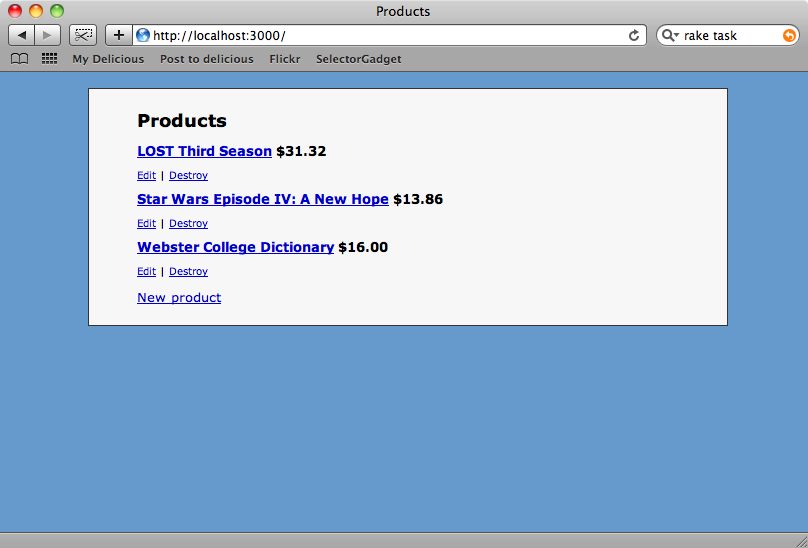
Now all of the products have prices based on Walmart’s.
With Nokogiri and SelectorGadget we’ve successfully extracted data from another website. Together they’re a powerful pair of tools to help you screen-scrape. But what if you need to interact more with the website, say, logging in before extracting data? For this we can use Mechanize, which we’ll be showing in the next episode.